Hadoop Eco System - An Overview
Different distributions of Hadoop
| Hadoop Distribution | Advantages | Disadvantages |
|---|---|---|
| Cloudera Distribution for Hadoop (CDH) | CDH has a user friendly interface with many features and useful tools like Cloudera Impala | CDH is comparatively slower than MapR Hadoop Distribution |
| MapR Hadoop Distribution | It is one of the fastest hadoop distribution with multi node direct access. | MapR does not have a good interface console as Cloudera |
| Hortonworks Data Platform (HDP) | It is the only Hadoop Distribution that supports Windows platform. | The Ambari Management interface on HDP is just a basic one and does not have many rich features. |
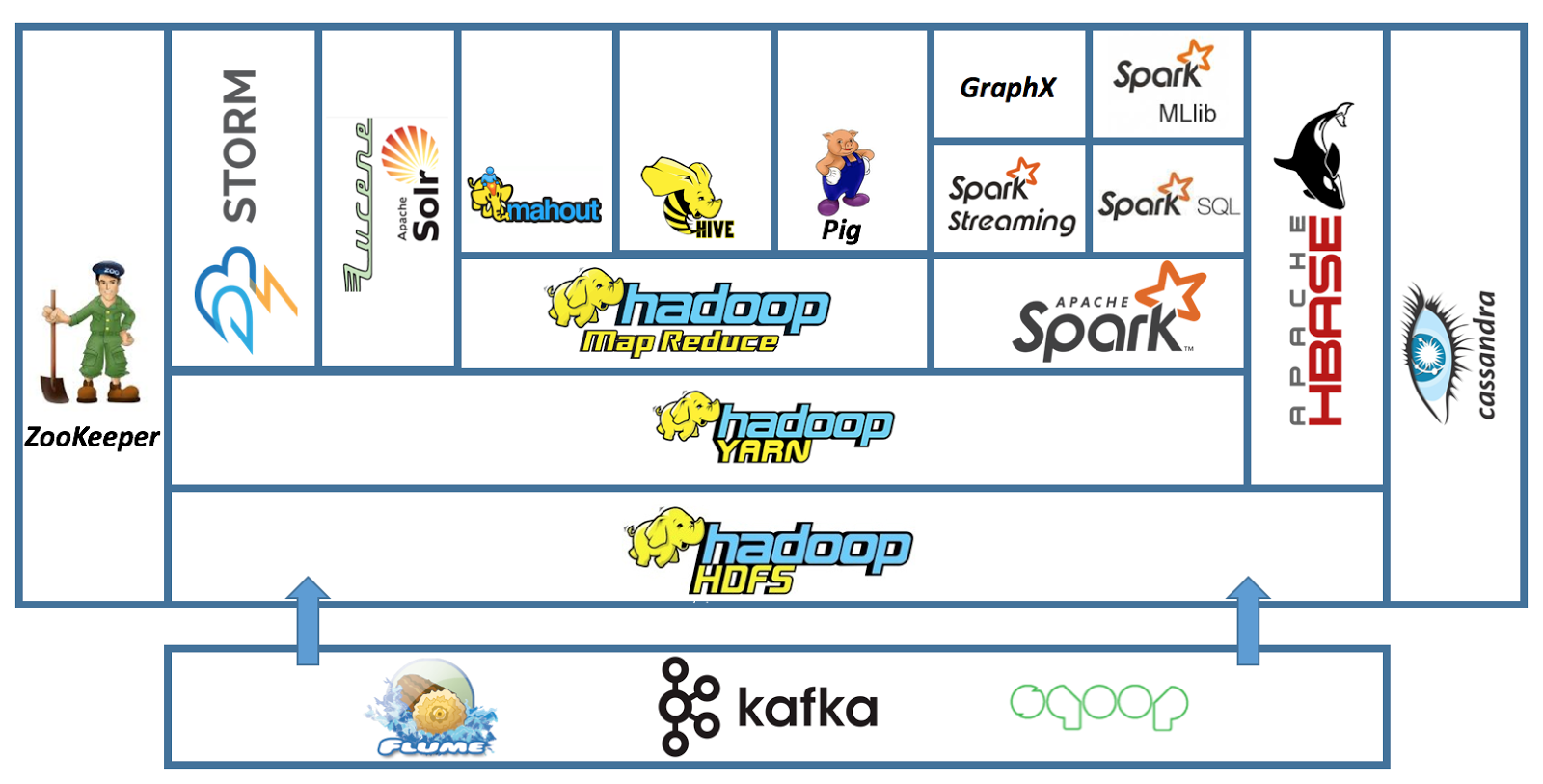
Big data toolsets
Hadoop
Hadoop is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Terminology
- PayLoad - Applications implement the Map and Reduce functions, forming the core of the job.
- Mapper - A Mapper maps the input key/value pairs to a set of intermediate key/value pairs.
- NamedNode - A node that manages the Hadoop Distributed File System (HDFS).
- DataNode - A node where data is presented in advance before any processing takes place.
- MasterNode - A node where JobTracker runs and accepts job requests from clients.
- SlaveNode - A node where the Map and Reduce program runs.
- JobTracker - Schedules jobs and tracks assigned jobs to TaskTracker.
- TaskTracker - Tracks tasks and reports status to JobTracker.
- Job - An execution of a Mapper and Reducer across a dataset.
- Task - An execution of a Mapper or Reducer on a slice of data.
- Task Attempt - A particular instance of an attempt to execute a task on a SlaveNode.
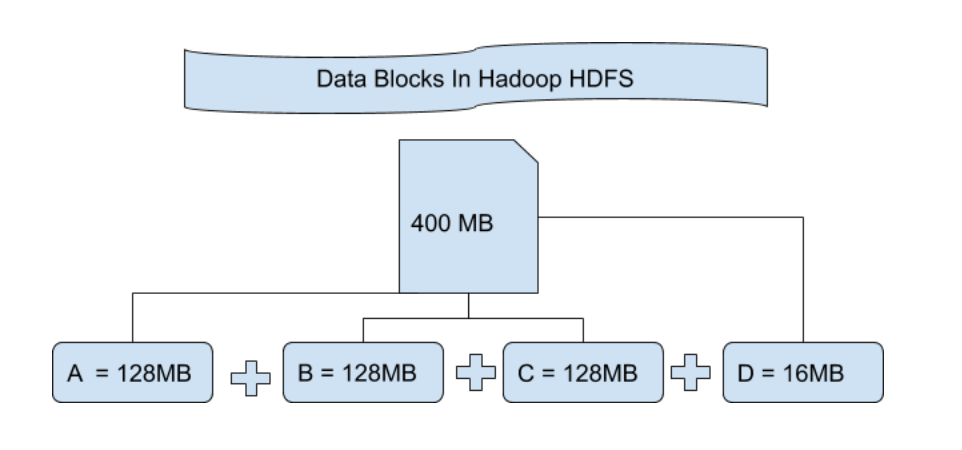
HDFS
HDFS is a distributed file system that stores data on commodity hardware. It provides high-throughput access to application data and is suitable for applications that have large data sets.
MapReduce
MapReduce is a programming model for processing and generating large data sets. It is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
Yarn
Yarn is a resource management platform responsible for managing computing resources in clusters and using them for scheduling of users’ applications.
Spark
Spark is a fast and general engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python, and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Hive
Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query and analysis. It provides a mechanism to project structure on top of a variety of data formats and provides a simple SQL-like language called HiveQL to query the data.
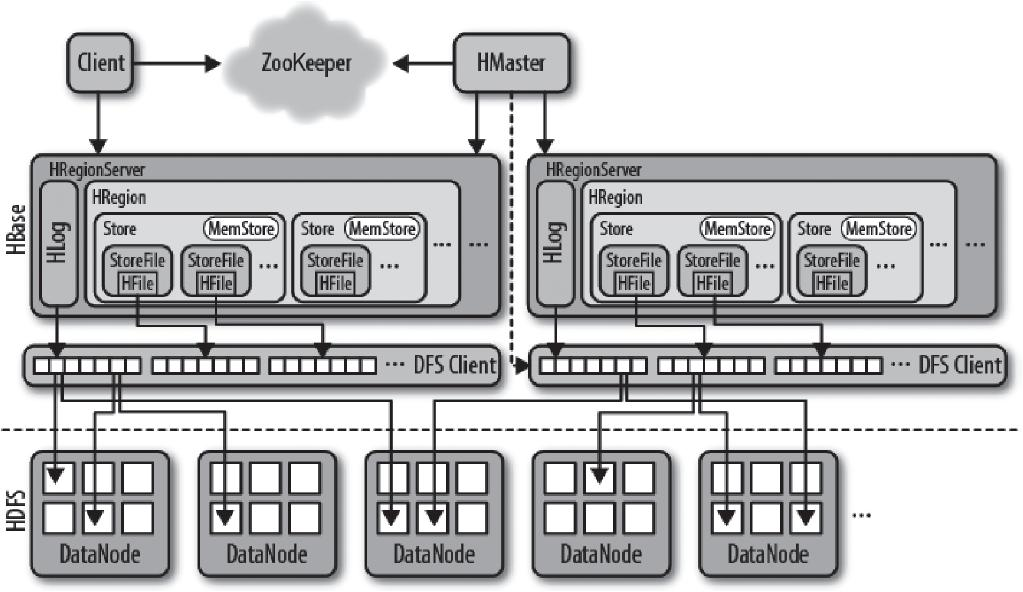
Hbase
Hbase is a distributed, scalable, big data store. It is an open-source, column-oriented, distributed database and is written in Java. It is developed as part of Apache Software Foundation’s Apache Hadoop project and runs on top of HDFS (Hadoop Distributed File System), providing Bigtable-like capabilities for Hadoop.
Pig
Pig latin is a high-level language for analyzing large data sets that consists of a set of data flow statements. It is compiled into a map reduce job and executed on Hadoop.
Hue
Hue is a web-based interactive query editor that enables you to interact with data warehouses. For example, the following image shows a graphic representation of Impala SQL query results that you can generate with Hue.
Flink
Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Storm
Storm is a distributed, fault-tolerant, real-time computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use!
Zeppelin
Zeppelin is an open-source web-based notebook for data analysis, visualization, and collaboration. It allows users to work with multiple programming languages like Python, R, SQL, and Scala in a single notebook interface. Zeppelin was first released in 2016 and has since become a popular tool for data scientists, researchers, and analysts.
Sqoop
Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.

Reference
https://www.datacamp.com/tutorial/tutorial-cloudera-hadoop-tutorial