Big Data Toolset - Summary
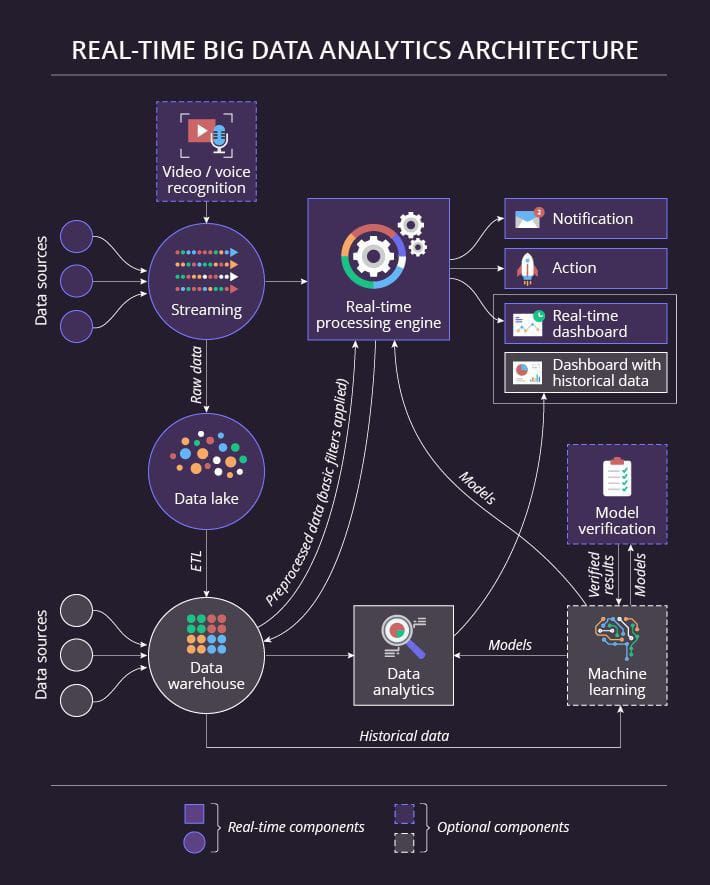
I. Hadoop related tools
Hadoop
Apache’s Hadoop project has almost become synonymous with big data. It has grown into a complete ecosystem with numerous open-source tools for highly scalable distributed computing.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://hadoop.apache.org
Ambari
As part of the Hadoop ecosystem, this Apache project provides a web-based intuitive interface for configuring, managing, and monitoring Hadoop clusters. Some developers want to integrate Ambari’s functionality into their own applications, and Ambari also provides them with APIs that make full use of REST (Representational State Transfer).
Supported operating systems: Windows, Linux, and OS X.
Related link: http://ambari.apache.org
Avro
This Apache project provides a data serialization system with rich data structures and a compact format. The schema is defined using JSON, making it easy to integrate with dynamic languages.
Supported operating systems: platform-independent.
Related link: http://avro.apache.org
Cascading
Cascading is a Hadoop-based application development platform that provides commercial support and training services.
Supported operating systems: platform-independent.
Related link: http://www.cascading.org/projects/cascading/
Chukwa
Based on Hadoop, Chukwa can collect data from large distributed systems for monitoring. It also includes tools for analyzing and displaying data.
Supported operating systems: Linux and OS X.
Related link: http://chukwa.apache.org
Flume
Flume can collect log data from other applications and send it to Hadoop. The official website claims: “It is powerful, fault-tolerant, and has reliable mechanisms for adjusting optimization and many fault-switching and recovery mechanisms.”
Supported operating systems: Linux and OS X.
Related link: https://cwiki.apache.org/confluence/display/FLUME/Home
HBase
HBase is a distributed database designed for large tables with billions of rows and millions of columns, providing random real-time read/write access to big data. It is similar to Google’s Bigtable but built on Hadoop and the Hadoop Distributed File System (HDFS).
Supported operating systems: platform-independent.
Related link: http://hbase.apache.org
Hadoop Distributed File System (HDFS)
HDFS is a file system for Hadoop, but it can also be used as a standalone distributed file system. It is based on Java and has fault tolerance, high scalability, and high configurability.
Supported operating systems: Windows, Linux, and OS X.
Related link: https://hadoop.apache.org/
Hive
Apache Hive is a data warehouse for the Hadoop ecosystem. It allows users to query and manage big data using HiveQL, a SQL-like language.
Supported operating systems: platform-independent.
Related link: http://hive.apache.org
Hivemall
Hivemall combines various machine learning algorithms for Hive. It includes many highly scalable algorithms for data classification, recursion, recommendation, k-nearest neighbor, anomaly detection, and feature hashing.
Supported operating systems: platform-independent.
Related link: https://github.com/myui/hivemall
Mahout
According to the official website, the purpose of the Mahout project is “to create an environment for quickly building scalable, high-performance machine learning applications.” It includes many algorithms for data mining on Hadoop MapReduce, as well as some novel algorithms for Scala and Spark environments.
Supported operating systems: platform-independent.
Related link: http://mahout.apache.org
MapReduce
As an indispensable part of Hadoop, the MapReduce programming model provides a way to process large distributed data sets. It was originally developed by Google, but is now also used by several other big data tools introduced in this article, including CouchDB, MongoDB, and Riak.
Supported operating systems: platform-independent.
Related link: http://hadoop.apache.org
Oozie
This workflow scheduling tool is designed specifically for managing Hadoop tasks. It can trigger tasks based on time or data availability and integrates with MapReduce, Pig, Hive, Sqoop, and many other related tools.
Supported operating systems: Linux and OS X.
Related link: http://oozie.apache.org
Pig
Apache Pig is a platform for distributed big data analysis. It relies on a programming language called Pig Latin and has advantages such as simplified parallel programming, optimization, and scalability.
Supported operating systems: platform-independent.
Related link: http://pig.apache.org
Sqoop
Enterprises often need to transfer data between relational databases and Hadoop, and Sqoop is a tool that can accomplish this task. It can import data into Hive or HBase and export from Hadoop to relational database management systems (RDBMS).
Supported operating systems: platform-independent.
Related link: http://sqoop.apache.org
Spark
As an alternative to MapReduce, Spark is a data processing engine. It claims to be up to 100 times faster than MapReduce when used in memory and up to 10 times faster when used on disk. It can be used with Hadoop and Apache Mesos or as a standalone tool.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://spark.apache.org
Tez
Built on Apache Hadoop YARN, Tez is “an application framework that allows building a complex directed acyclic graph of tasks for processing data.” It allows Hive and Pig to simplify complex tasks that would otherwise require multiple steps to complete.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://tez.apache.org
Zookeeper
This big data management tool claims to be “a centralized service that can be used for maintaining configuration information, naming, providing distributed synchronization, and providing group services.” It allows nodes in a Hadoop cluster to coordinate with each other.
Supported operating systems: Linux, Windows (only for development environments), and OS X (only for development environments).
Related link: http://zookeeper.apache.org
II. Big Data Analysis Platforms and Tools
Disco
Disco was initially developed by Nokia and is a distributed computing framework that is based on MapReduce, much like Hadoop. It includes a distributed file system and a database that supports billions of key-value pairs.
Supported Operating Systems: Linux and OS X.
Related Link: http://discoproject.org
HPCC
As an alternative to Hadoop, the HPCC big data platform promises very fast speed and scalability. In addition to the free community edition, HPCC Systems also offers paid enterprise editions, modules, training, consulting, and other services.
Supported Operating Systems: Linux.
Related Link: http://hpccsystems.com
Lumify
Lumify is owned by Altamira Technologies, which is known for its national security technologies and is an open source big data integration, analysis, and visualization platform. You can try out the demo version at Try.Lumify.io (http://try.lumify.io/) to see its actual effect.
Supported Operating Systems: Linux.
Related Link: http://www.jboss.org/infinispan.html
Pandas
The Pandas project includes data structures and data analysis tools based on the Python programming language. It allows organizations to use Python as an alternative to R for big data analysis projects.
Supported Operating Systems: Windows, Linux, and OS X.
Related Link: http://pandas.pydata.org
Storm
Storm is now an Apache project and provides real-time processing of big data (unlike Hadoop, which only provides batch task processing). Its users include Twitter, The Weather Channel, WebMD, Alibaba, Yelp, Yahoo Japan, Spotify, Group, Flipboard, and many other companies.
Supported Operating Systems: Linux.
Related Link: https://storm.apache.org
Section 3: Databases/Data Warehouses
Blazegraph
Previously called “Bigdata”, Blazegraph is a highly scalable, high-performance database. It has both open source and commercial versions.
Supported Operating Systems: Operating system independent.
Related Link: http://www.systap.com/bigdata
Cassandra
This NoSQL database was originally developed by Facebook and is now used by over 1,500 organizations, including Apple, CERN, Comcast, Electronic Harbour, GitHub, GoDaddy, Hulu, Instagram, Intuit, Netflix, Reddit, and others. It can support massively large clusters; for example, Apple’s Cassandra system includes over 75,000 nodes and has a data volume of over 10 PB.
Supported Operating Systems: Operating system independent.
Related Link: http://cassandra.apache.org
CouchDB
CouchDB is known as “a database that fully embraces the web.” It stores data in JSON documents, which can be queried through a web browser and processed with JavaScript. It is easy to use and has high availability and scalability in a distributed network.
Supported Operating Systems: Windows, Linux, OS X, and Android.
Related Link: http://couchdb.apache.org
FlockDB
FlockDB, developed by Twitter, is a very fast and highly scalable graph database that is good at storing social network data. Although it is still available for download, the open source version of this project has not been updated for some time.
Supported Operating Systems: Operating system independent.
Related Link: https://github.com/twitter/flockdb
Hibari
This Erlang-based project claims to be a “distributed ordered key-value storage system with strong consistency.” It was originally developed by Gemini Mobile Technologies and is now used by several telecom operators in Europe and Asia.
Supported Operating Systems: Operating system independent.
Related Link: http://hibari.github.io/hibari-doc/
Hypertable
Hypertable is a big data database that is compatible with Hadoop and promises high performance. Its users include Electronic Harbour, Baidu, Gaopeng, Yelp, and many other Internet companies. It provides commercial support services.
Supported Operating Systems: Linux and OS X.
Related Link: http://hypertable.org
Impala
Cloudera claims that the SQL-based Impala database is “the leading open source analytic database for Apache Hadoop.” It can be downloaded as a standalone product and is also part of Cloudera’s commercial big data product.
Supported Operating Systems: Linux and OS X.
Related Link: http://www.cloudera.com
InfoBright Community Edition
Designed for data analysis, InfoBright is a column-oriented database with high compression rates. InfoBright.com (http://infobright.com/) offers fee-based products based on the same code, as well as support services.
Supported Operating Systems: Windows and Linux.
Related Link: http://www.infobright.org
MongoDB
MongoDB has been downloaded over 10 million times and is an extremely popular NoSQL database. MongoDB.com offers enterprise editions, support, training, and related products and services.
Supported Operating Systems: Windows, Linux, OS X, and Solaris.
Related Link: http://www.mongodb.org
Neo4j
Neo4j claims to be “the fastest and most scalable native graph database” and promises massive scalability, fast cipher query performance, and improved development efficiency. Its users include Electronic Harbour, Pitney Bowes, Walmart, Lufthansa, and CrunchBase.
Supported Operating Systems: Windows and Linux.
Related Link: http://neo4j.org
OrientDB
This multi-model database combines some of the features of a graph database and some of the features of a document database. It offers fee-based support, training, and consulting services.
Supported Operating Systems: Operating system independent.
Related Link: http://www.orientdb.org/index.htm
Pivotal Greenplum Database
Pivotal claims that Greenplum is “the best-in-class enterprise analytic database” and can perform powerful analysis on massive amounts of data very quickly. It is part of Pivotal’s big database suite.
Supported Operating Systems: Windows, Linux, and OS X.
Related Link: http://pivotal.io/big-data/pivotal-greenplum-database
Riak
Riak is “feature complete” and has two versions: KV is a distributed NoSQL database, and S2 provides cloud-oriented object storage. It has both open source and commercial versions and has attachments that support Spark, Redis, and Solr.
Supported Operating Systems: Linux and OS X.
Related Link: http://basho.com/riak-0-10-is-full-of-great-stuff/
Redis
Redis is now sponsored by Pivotal and is a key-value caching and storage system. It provides fee-based support. Note: Although the project does not officially support Windows, Microsoft has a Windows derivative version on GitHub.
Supported Operating Systems: Linux.
Related Link: http://redis.io
IV. Business Intelligence
Talend Open Studio
Talend has been downloaded over 2 million times and provides open source software for data integration. The company also develops paid tools for big data, cloud, data integration, application integration, and master data management. Its users include corporate organizations such as AIG, Comcast, Electron port, General Electric, Samsung, Ticketmaster, and Verizon.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://www.talend.com/index.php
Jaspersoft
Jaspersoft provides flexible, embeddable business intelligence tools and is used by many corporate organizations, including HighSoft, Crown Group Technology, the US Department of Agriculture, Ericsson, Time Warner Cable, Olympic Steel, the University of Nebraska-Lincoln, and General Electric. In addition to the open source community edition, it also offers paid reporting editions, Amazon Web Services (AWS) editions, professional editions, and enterprise editions.
Supported operating systems: Operating system independent.
Related link: http://www.jaspersoft.com
Pentaho
Pentaho is owned by Hitachi Data Systems and provides a range of data integration and business analytics tools. The official website offers three community editions; visit Pentaho.com for information on supported paid editions.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://community.pentaho.com
SpagoBI
Spago is referred to as the “open source leader” by market analysts and provides business intelligence, middleware, and quality assurance software, as well as a Java EE application development framework. The software is 100% free and open source, but also offers paid support, consulting, training, and other services.
Supported operating systems: Operating system independent.
Related link: http://www.spagoworld.org/xwiki/bin/view/SpagoWorld/
KNIME
KNIME stands for “Konstanz Information Miner”, an open source analytics and reporting platform. It provides several commercial and open source extensions to enhance its functionality.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://www.knime.org
BIRT
BIRT stands for “Business Intelligence and Reporting Tools.” Its platform can be used to create visual elements and reports that can be embedded in applications and websites. It is part of the Eclipse community and is supported by Actuate, IBM, and Innovent Solutions.
Supported operating systems: Operating system independent.
Related link: http://www.eclipse.org/birt/
V. Data Mining
DataMelt
As a successor to jHepWork, DataMelt can handle mathematical operations, data mining, statistical analysis, and data visualization tasks. It supports Java and related programming languages, including Jython, Groovy, JRuby, and Beanshell.
Supported operating systems: Operating system independent.
Related link: http://jwork.org/dmelt/
KEEL
KEEL stands for “Knowledge Extraction based on Evolutionary Learning” and is a Java-based machine learning tool that provides algorithms for a range of big data tasks. It also helps evaluate the effectiveness of algorithms when dealing with tasks such as recursion, classification, clustering, pattern mining, and similar tasks.
Supported operating systems: Operating system independent.
Related link: http://keel.es
Orange
Orange believes that data mining should be “fruitful and fun”, regardless of whether you have years of experience or are just starting out in the field. It provides visual programming and Python scripting tools for data visualization and analysis.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://orange.biolab.si
RapidMiner
RapidMiner claims to have over 250,000 users, including PayPal, Deloitte, Electron port, Cisco, and Volkswagen. It provides a range of extensive open source and paid editions, but note that the free open source edition only supports CSV or Excel format data.
Supported operating systems: Operating system independent.
Related link: https://rapidminer.com
Rattle
Rattle stands for “The R Analytical Tool To Learn Easily.” It provides a graphical interface for the R programming language, simplifying processes such as building statistical or visualization summaries of data, building models, and executing data transformations.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://rattle.togaware.com
SPMF
SPMF now includes 93 algorithms for sequence pattern mining, association rule mining, itemset mining, sequential rule mining, and clustering. It can be used independently or integrated into other Java-based programs.
Supported operating systems: Operating system independent.
Related link: http://www.philippe-fournier-viger.com/spmf/
Weka
Weka, or Waikato Environment for Knowledge Analysis, is a set of Java-based machine learning algorithms for data mining. It can perform data preprocessing, classification, regression, clustering, association rule mining, and visualization.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://www.cs.waikato.ac.nz/~ml/weka/
VI. Query Engine
Drill
This Apache project allows users to use SQL-based queries to query Hadoop, NoSQL databases, and cloud storage services. It can be used for data mining and ad-hoc queries and supports a wide range of databases, including HBase, MongoDB, MapR-DB, HDFS, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, and Swift.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://drill.apache.org
VII. Programming Language
R
R is similar to the S language and environment and is designed for statistical computing and graphics. It includes an integrated set of big data tools for data processing, computation, and visualization.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://www.r-project.org
ECL
Enterprise Control Language (ECL) is a language for developers to build big data applications on the HPCC platform. The HPCC Systems website offers integrated development environments (IDEs), tutorials, and numerous related tools for working with the language.
Supported operating systems: Linux.
Related link: http://hpccsystems.com/download/docs/ecl-language-reference
VIII. Big Data Search
Lucene
Java-based Lucene can perform full-text searches very quickly. According to the official website, it can retrieve over 150GB of data per hour on modern hardware and contains powerful and efficient search algorithms. Development work is sponsored by the Apache Software Foundation.
Supported operating systems: Operating system independent.
Related link: http://lucene.apache.org/core/
Solr
Solr is based on Apache Lucene and is a highly reliable, highly scalable enterprise search platform. Well-known users include eHarmony, Sears, StubHub, Zappos, Best Buy, AT&T, Instagram, Netflix, Bloomberg, and Travelocity.
Supported operating systems: Operating system independent.
Related link: http://lucene.apache.org/solr/
IX. In-Memory Technology
Ignite
This Apache project is a “high-performance, integrated, distributed in-memory platform for performing real-time computing and processing on massive data sets, with speeds several orders of magnitude greater than traditional disk-based or flash-based technologies.” The platform includes features such as data grids, compute grids, service grids, streaming, Hadoop acceleration, advanced clustering, file systems, messaging, events, and data structures.
Supported operating systems: Operating system independent.
Related link: https://ignite.incubator.apache.org
Terracotta
Terracotta claims that its BigMemory technology is “one of the world’s leading in-memory data management platforms”, with 2.1 million developers and software deployed by 250 corporate organizations. The company also provides commercial software and support, consulting, and training services.
Supported operating systems: Operating system independent.
Related link: http://www.terracotta.org
Pivotal GemFire/Geode
Earlier this year, Pivotal announced that it would open source key components of its big data suite. GemFire/Geode provides an in-memory data grid that supports transaction processing, real-time analytics, and continuous processing.
Supported operating systems: Operating system independent.
Related link: https://pivotal.io/big-data/pivotal-gemfire
GridGain
GridGain, powered by Apache Ignite, provides in-memory data structures for processing big data quickly and also offers a Hadoop accelerator based on the same technology. It has both a paid enterprise edition and a free community edition, which includes free basic support.
Supported operating systems: Windows, Linux, and OS X.
Related link: http://www.gridgain.com
Infinispan
As a Red Hat JBoss project, Java-based Infinispan is a distributed in-memory data grid. It can be used as a cache, a high-performance NoSQL database, or to add clustering capabilities to many frameworks.
Supported operating systems: OS independent.