Logging

Introduction
Logging is a critical aspect of any software application or system. It involves recording information about the program’s execution, such as when certain events occur, what data was processed, and any errors that were encountered. This information can be used to understand how the program is behaving, identify bugs, and troubleshoot issues.
There are several different types of logs that can be generated by an application, such as:
- System logs: These logs contain information about the operating system and hardware, such as startup and shutdown messages, system errors, and resource usage.
- Application logs: These logs contain information specific to the application, such as user actions, business-specific events, and errors.
- Access logs: These logs contain information about client connections to the application, such as the IP address, request method, and response status.
- Performance logs: These logs contain information about the application’s performance, such as response time, memory usage, and CPU usage.
When logging an application, it’s important to consider the following best practices:
- Use a consistent format: This makes it easier to parse and analyze the logs. The most widely used format is JSON, it is human-readable, easy to parse and can be easily integrated with other tools.
- Include relevant information: Logs should contain enough information to understand what is happening within the application. This may include the state of variables, input and output data, and any relevant error messages.
- Use appropriate log levels: Different types of information should be logged at different levels. For example, error messages should be logged at the highest level, while informational messages can be logged at a lower level.
- Rotate the logs: Logs can grow large over time, and it’s important to rotate them to prevent them from consuming too much disk space.
- Centralized logging: Collecting all logs in a central location allows for easier analysis and troubleshooting. There are many logging platforms like ELK (Elasticsearch, Logstash and Kibana) and Fluentd which can help to centralize the logs from different sources.
- Secure the logs: Logs contain sensitive information, so it’s important to ensure that they are protected from unauthorized access.
Logging severities
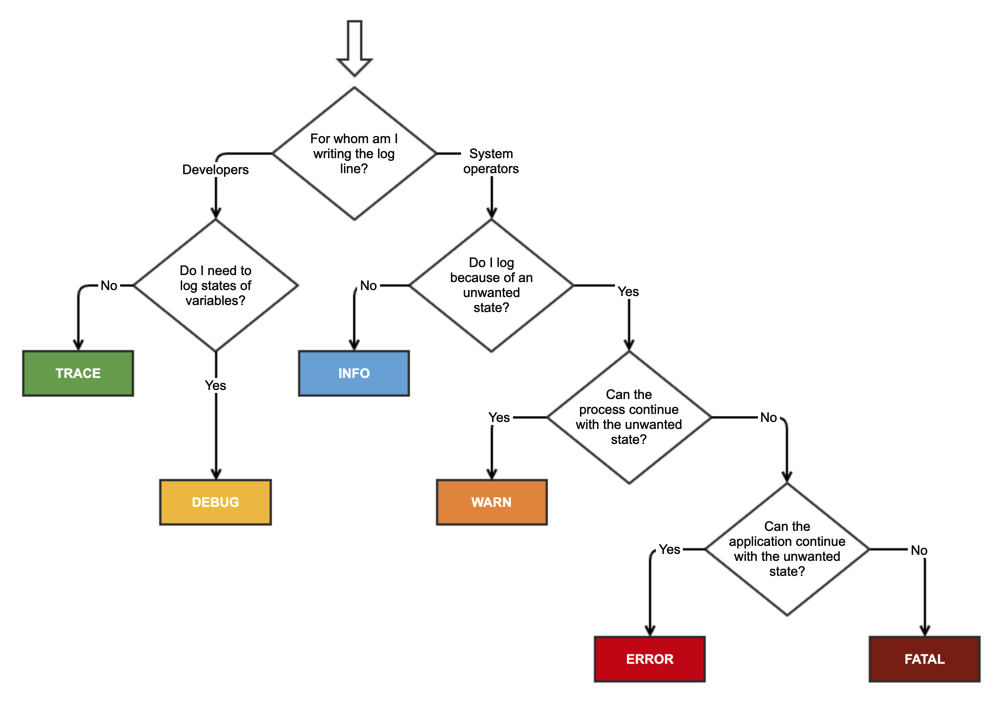
Fatal/Critical: This indicates an overall application or system failure that should be investigated immediately. The SysAdmin should be alerted, but only if it is truly necessary. This severity level should be used sparingly, as it is reserved for critical issues that may cause significant harm to the system. Typically, a Fatal error only occurs once in the lifetime of a process. If the log file is tied to the process, this is typically the last message in the log.
Error: This indicates a problem that should be investigated. The SysAdmin should be notified automatically, but there is no need to wake them up. By filtering the log to show errors and above, you can get an overview of error frequency and quickly identify the initiating failure that might have resulted in a cascade of additional errors. Tracking error rates versus application usage can yield useful quality metrics such as MTBF, which can be used to assess overall quality. For example, this metric might help inform decisions about whether or not another beta testing cycle is needed before a release.
Warning: This may or may not indicate a problem. For example, expected transient environmental conditions such as a short loss of network or database connectivity should be logged as Warnings, not Errors. Viewing a log filtered to show only warnings and errors may give quick insight into early hints at the root cause of a subsequent error. Warnings should be used sparingly so that they don’t become meaningless. For example, loss of network access should be a warning or even an error in a server application, but might be just an Info in a desktop app designed for occasionally disconnected laptop users.
Info: This indicates important information that should be logged under normal conditions, such as successful initialization, services starting and stopping, or the successful completion of significant transactions. Viewing a log showing Info and above should give a quick overview of major state changes in the process, providing top-level context for understanding any warnings or errors that also occur. Don’t have too many Info messages. We typically have less than 5% of Info messages relative to Trace.
Trace: This is the most commonly used severity level, and should provide context to understand the steps leading up to errors and warnings. Having the right density of Trace messages makes software much more maintainable, but requires some diligence because the value of individual Trace statements may change over time as programs evolve. The best way to achieve this is by getting the dev team in the habit of regularly reviewing logs as a standard part of troubleshooting customer reported issues. Encourage the team to prune out Trace messages that no longer provide useful context and to add messages where needed to understand the context of subsequent messages. For example, it is often helpful to log user input such as changing displays or tabs.
Debug: We consider Debug to be less severe than Trace. The distinction is that Debug messages are compiled out of Release builds. That said, we discourage the use of Debug messages. Allowing Debug messages tends to lead to more and more Debug messages being added and none ever removed. Over time, this makes log files almost useless because it’s too hard to filter signal from noise. This causes developers to not use the logs, which continues the death spiral. In contrast, constantly pruning Trace messages encourages developers to use them, which results in a virtuous spiral. Also, this eliminates the possibility of bugs being introduced because of needed side-effects in debug code that isn’t included in the release build. While this shouldn’t happen in good code, it’s better to be safe than sorry.
How to choose Logging Levels
Conclusion
In conclusion, logging is an essential tool for understanding the behavior of a software application or system. By following best practices for logging, developers can create logs that are easy to read, understand, and use for troubleshooting and problem-solving. Centralized logging and log rotation are also important to ensure that logs don’t consume too much disk space and can be easily accessible. Logs security is also essential to protect sensitive information.
Reference
- What is Logging? (
https://www.datadoghq.com/blog/observability/) https://en.wikipedia.org/wiki/Sysloghttps://sematext.com/blog/logging-levels/https://stackoverflow.com/questions/2031163/when-to-use-the-different-log-levels