Introduction to Zookeeper

ZooKeeper is an open-source implementation based on the Google Chubby paper. It solves the problem of distributed data consistency and facilitates applications that rely on it to implement functions such as data publishing/subscription, load balancing, service registration and discovery, distributed coordination, event notification, cluster management, leader election, distributed locks, and queues.
Basic Concepts
Cluster Roles
In a distributed system, each machine that makes up a cluster generally has its own role. The most typical cluster model is the Master/Slave model, in which the machines capable of handling all write operations are called Master nodes, and all machines that obtain the latest data through asynchronous replication and provide read services are called Slave nodes.
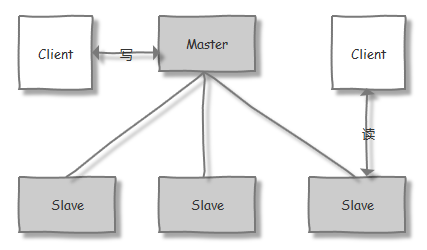
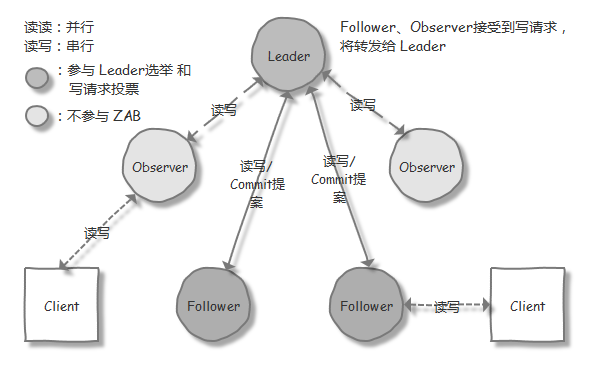
ZooKeeper introduces three roles: Leader, Follower, and Observer, and corresponding states: Leading, Following, Observing, and Looking. In a ZooKeeper cluster, a leader election process is used to select a node as the leader node, which provides read and write services to clients. Follower and Observer nodes can provide read services, but the only difference is that Observer machines do not participate in the leader election process and the “over half write success” policy for write operations. Observers are only notified of proposals that have already been committed. Therefore, Observers can improve the read performance of the cluster without affecting the write performance (see the “Performance Optimization - Optimization Strategies - Observer Mode” section for details).
Session
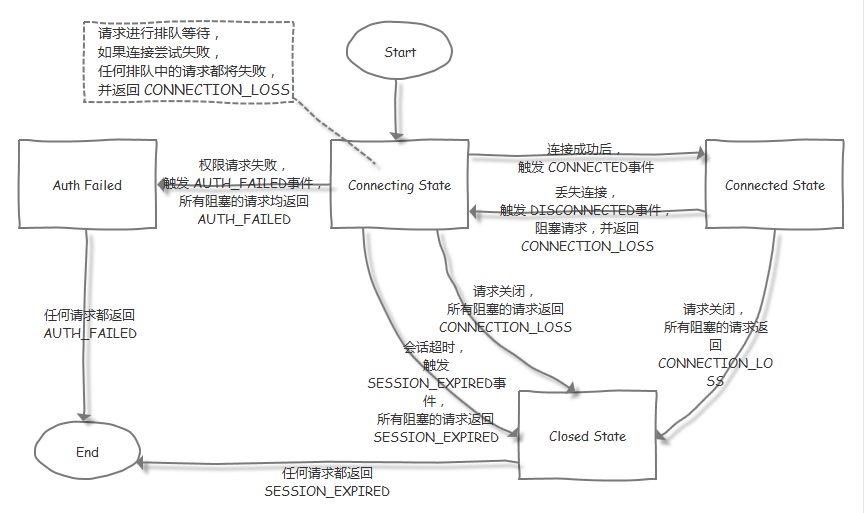
A session in ZooKeeper refers to a client’s TCP long connection with the server. When a client starts, it establishes a TCP connection with the server, and the client session’s lifecycle begins from the first connection. Through this connection, the client can maintain an effective session with the server through heartbeat detection, send requests to and receive responses from the ZooKeeper server, and receive watch event notifications from the server.
The sessionTimeout parameter is used to control the timeout period of a client session. When the server is under too much pressure or the network fails for various reasons, the client will automatically try to reconnect to each server in the ZooKeeper address list one by one (the retry strategy can be implemented using Curator). As long as a connection to any server in the cluster can be reestablished within the time specified by sessionTimeout, the previously created session will still be valid. If reconnected outside of the sessionTimeout period, SESSION_EXPIRED will be notified because the session has been cleared, and the program needs to recover temporary data.
There is also a situation where the data rebuilt after the session is moved to a new node is overwritten by a write request that arrives late due to network latency. This issue was raised in ZOOKEEPER-417, and a SessionMovedException was added to this JIRA so that clients rebuilding a session with the same sessionld/sessionPasswd can be aware of it. However, this issue has not been resolved well in ZOOKEEPER-2219.
Data Model
In ZooKeeper, nodes are divided into two types: machine nodes, which make up the cluster, and data nodes or ZNodes, which are the data units in the data model. ZooKeeper stores all data in memory, and the structure of the data model is similar to a tree (ZNode Tree), where each path separated by slashes (/) is a ZNode, such as /foo/path1. Each ZNode contains its own data content and a series of attribute information.
ZNodes can be persistent or ephemeral. Persistent nodes are nodes that will be saved on ZooKeeper unless they are actively removed. The lifecycle of ephemeral nodes is bound to the client session. Once the client session is invalidated, all ephemeral nodes created by this client will be removed. In HBase, the cluster monitors the addition and shutdown of HRegionServer processes and the Active status of HMaster processes through two ephemeral nodes, /hbase/rs/* and /hbase/master.
ZooKeeper also has a type of sequential node (SEQUENTIAL). When this node is created, ZooKeeper will automatically add a suffix of an incrementing integer maintained by the parent node to its child node name (upper limit: Integer.MAX_VALUE). The characteristics of this node can be applied to persistent/ephemeral nodes, combined into persistent sequential nodes (PERSISTENT_SEQUENTIAL) and ephemeral sequential nodes (EPHEMERAL_SEQUENTIAL).
Version
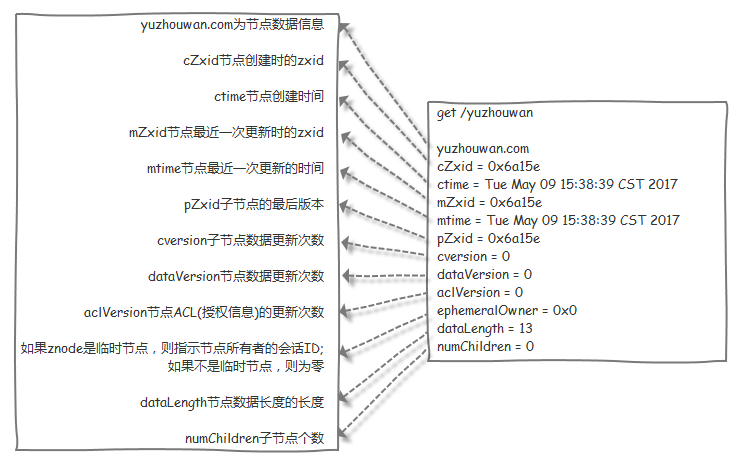
Each ZNode in ZooKeeper stores data, and for each ZNode, ZooKeeper maintains a data structure called Stat, which records three data versions of this ZNode: version (the current version of the ZNode’s data content), cversion (the version of the ZNode’s child nodes), and aversion (the version of the ZNode’s ACL changes). These versions play a role in controlling the atomicity of ZooKeeper operations. For more details, see the “Source Code Analysis - Foothold - ZooKeeper Optimistic Locking” section.
If you want to make the operation of writing data support CAS, you can use the Versionable#withVersion method to specify the current data version when calling setData(). If the write is successful, it means that during the process of writing data, no other user has modified the content of the ZNode node. Otherwise, a KeeperException.BadVersionException will be thrown, indicating that the CAS write has failed. This approach helps to avoid the problem of mutual coverage that may occur during “concurrent local update of ZNode node content.”
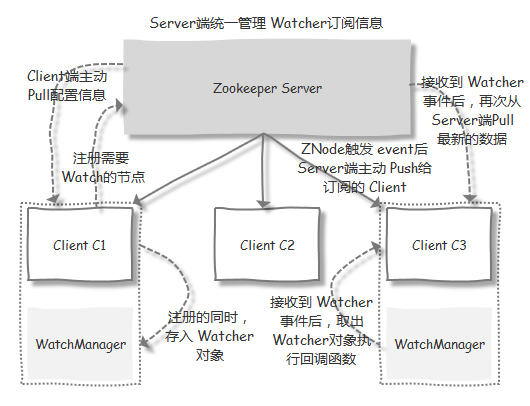
Watcher
Watcher is a publish/subscribe mechanism provided by ZooKeeper. Users can register Watchers on specified nodes, and when certain specific events are triggered, the ZooKeeper server notifies subscribed clients of the events. This mechanism is an important feature of ZooKeeper for implementing distributed coordination.
ACL
Similar to the Unix file system, ZooKeeper uses ACL (Access Control Lists) policies for permission control.
| Command | Comment |
|---|---|
| CREATE [c] | The permission to create a child node |
| READ [r] | The permission to obtain the node data and the list of child nodes |
| WRITE [w] | The permission to update the node data |
| DELETE [d] | The permission to delete the current node |
| ADMIN [a] | The permission to manage, can set the permission of the current node |
| Scheme | ID | Comment |
|---|---|---|
| world | anyone | Nodes in ZooKeeper that anyone has permission to belong to world:anyone |
| auth | No id required | Users authenticated through authentication have permission |
| digest | username:BASE64 (SHA1(password)) | Authentication is required in the form of username:password |
| ip | The id is the IP address (or IP address range) of the client machine | ip:192.168.1.0/14 indicates an IP range matching the first 14 bits |
| super | The corresponding id has super permission (CRWDA) |
Common Commands
| Command | Comment |
|---|---|
| conf | Output detailed information about relevant service configurations |
| cons | List detailed information about all clients’ connections/sessions that are connected to the server (including “received/sent” packet counts, session IDs, operation latency, last operation execution, etc.) |
| envi | Output detailed information about the server environment (different from the conf command) |
| dump | List unprocessed sessions and temporary nodes |
| stat | Check which node is selected as the Follower or Leader |
| ruok | Test whether the server is started, and if imok is replied, it means that it has been started |
| mntr | Output some runtime information (latency/packets/alive_connections/outstanding_requests/server_state/znode + watch + ephemerals count…) |
| reqs | List unprocessed requests |
| wchs | List brief information about the server’s watch |
| wchc | List detailed information about the server’s watch through session (the output is a list of sessions related to watch) |
| wchp | List detailed information about the server’s watch through the path (the output is a path related to the session) |
| srvr | Output all information about the service (can be used to check if the current node has synchronized the cluster data and is in Follower state) |
| srst | Reset server statistics |
| kill | Shut down the server |
Command Execution
echo <four-letter command> | nc IP 2181
Common Configuration
dataDir: The directory where ZooKeeper saves server snapshot files. By default, ZooKeeper also saves data log files in this directory (default: /tmp/zookeeper)dataLogDir: Used to store server transaction logsclientPort: The port on which clients connect to the ZooKeeper server. ZooKeeper listens on this port and accepts client access requests (default: 2181)tickTime(SS/CS): Used to indicate the smallest time unit for maintaining the heartbeat mechanism between servers or between clients and servers. The minimum session expiration time is twice the tickTime by default (default: 2000ms)initLimit(LF): The maximum number of heartbeats that can be tolerated between Leader nodes and Follower nodes when initially connecting in the cluster (default: 5 tickTime)syncLimit(LF): The maximum number of heartbeats that can be tolerated between Leader nodes and Follower nodes when requesting and responding in the cluster (default: 2 tickTime)minSessionTimeout&maxSessionTimeout: The default is 2 x tickTime - 20 x tickTime, which is used to control the session timeout time set by the client. If it exceeds or is less than this value, it will be automatically set by the server to the maximum or minimum.maxClientCnxns: Controls the upper limit of the number of connections created by a single client (identified by IP address), and setting it to 0 means no limit
References
https://zookeeper.apache.orghttps://yuzhouwan.com/posts/31915https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/chubby-osdi06.pdf