Site Reliability Engineering
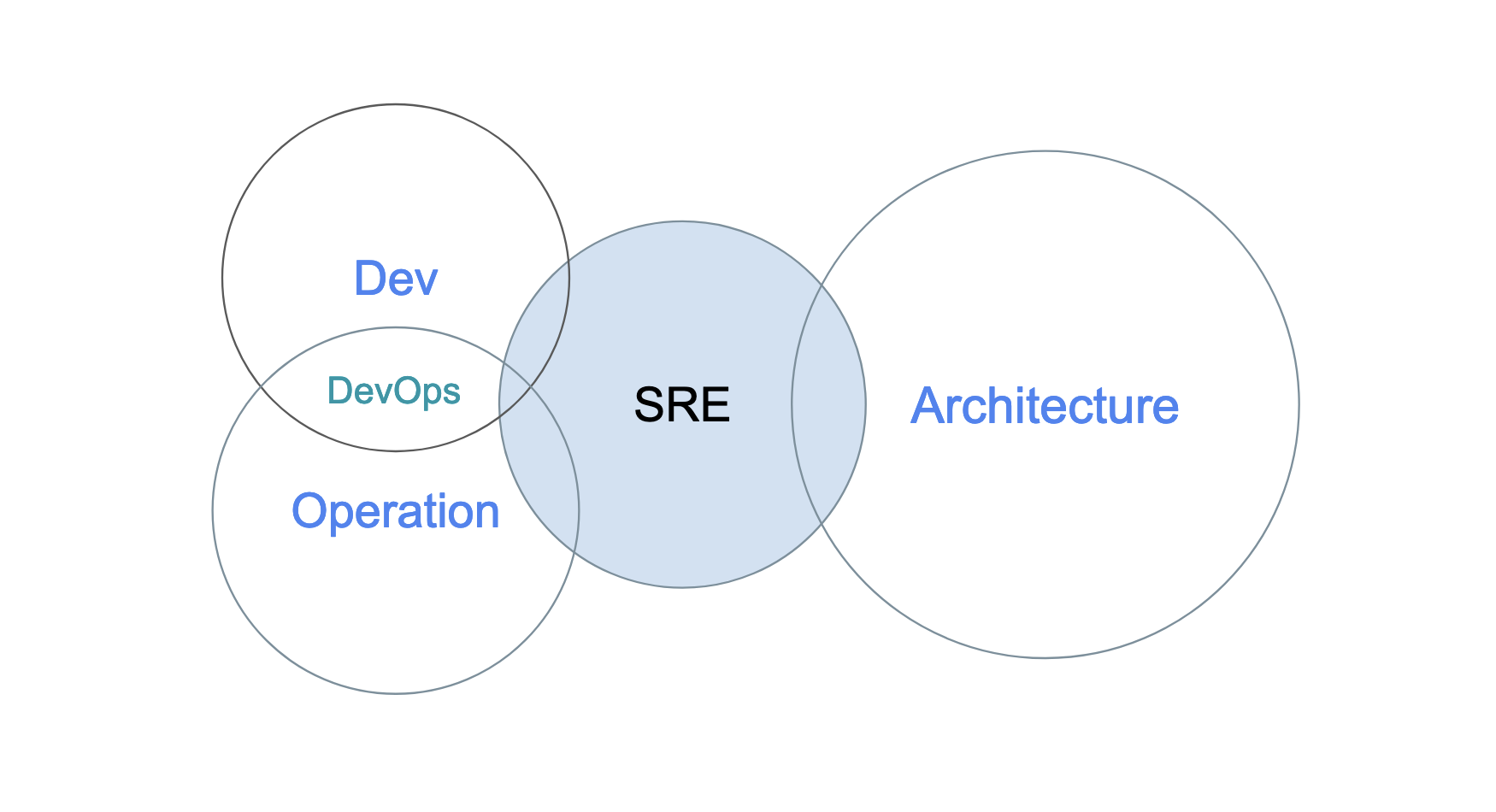
What is Site Reliability Engineering (SRE)?
Site Reliability Engineering (SRE) is an approach to managing and operating large-scale, complex software systems. It emerged as a discipline within the field of software engineering to address the growing need for reliable and scalable infrastructure. SRE combines software engineering principles with operational expertise to ensure service reliability, performance, and availability. By treating infrastructure and application configurations as part of the software release cycle, SREs can effectively manage and maintain complex systems.
The need for SRE arose due to the increasing complexity of modern software systems, which often involve distributed architectures, cloud platforms, and rapid deployment cycles. As organizations strive to provide highly available and reliable services, SRE has become instrumental in aligning development and operations teams, fostering collaboration, and establishing resilient systems that can handle the demands of today’s digital landscape.
Why Is SRE Important?
- Improved Reliability: SRE methodologies significantly enhance the reliability of software systems. By treating reliability as a product trait, SRE teams ensure that systems remain accessible even during unexpected outages. Furthermore, they address performance issues that could discourage customers and reduce revenue.
- Reduced Downtime: E-businesses heavily rely on their websites for revenue. Any operational interruption can harm a brand’s reputation and risk sales. SRE reduces these risks by ensuring uninterrupted system operations. Proactive monitoring and alerts help SRE teams detect and resolve issues early, preventing major setbacks.
- Increased Scalability: SRE can enhance system scalability. Automated infrastructure handling and deployment enable SRE teams to quickly allocate new resources as demand increases.
- Quick Recovery: SRE also reduces the mean time to recovery (MTTR) after incidents, ensuring fast problem resolution and minimizing business impact.
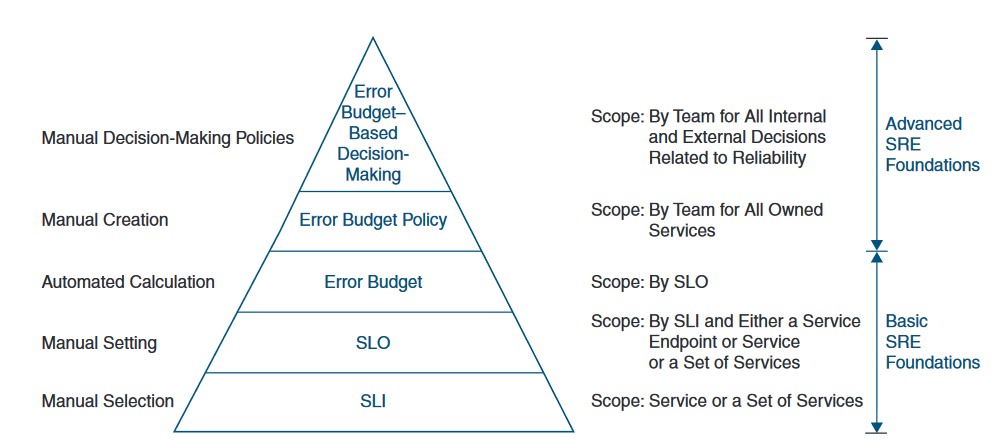
SRE Basic Concepts
Service level indicators
Service level indicators (SLIs) are a foundational concept in SRE. All the other concepts build on top of SLIs. In the book Site Reliability Engineering: How Google Runs Production Systems, an SLI is succinctly defined as “a service level indicator - a carefully defined quantitative measure of some aspect of the level of service that is provided.”
SLI
SLI = [Good events / Valid events] x 100
System Categories and Relevant SLIs
| System Type | Relevant SLIs | Questions Answered by SLIs |
|---|---|---|
| User-facing serving systems | Availability Latency Throughput |
Could we respond to the request? How long did it take to respond? How many requests could be handled? |
| Storage systems | Availability Durability Throughput |
How long does it take to read or write data? Can we access the data on demand? Is the data still there when we need it? |
| Big data systems | Throughput End-to-end latency |
How much data is being processed? How long does it take the data to progress from ingestion to completion? |
Service Level Objectives
Whereas SLIs are about customer expectations, SLOs are about how those expectations will be met.
| Reliability level | Per year | Per quarter | Per 30 days |
|---|---|---|---|
| 90% | 36.5 days | 9 days | 3 days |
| 95% | 18.25 days | 4.5 days | 1.5 days |
| 99% | 3.65 days | 21.6 hours | 7.2 hours |
| 99.5% | 1.83 days | 10.8 hours | 3.6 hours |
| 99.9% | 8.76 hours | 2.16 hours | 43.2 minutes |
| 99.95% | 4.38 hours | 1.08 hours | 21.6 minutes |
| 99.99% | 52.6 minutes | 12.96 minutes | 4.32 minutes |
| 99.999% | 5.26 minutes | 1.30 minutes | 25.9 seconds |
Error Budget
Error Budget
error budget = maximum service level – SLO threshold
SRE Concept Pyramid
General Practices
Principles
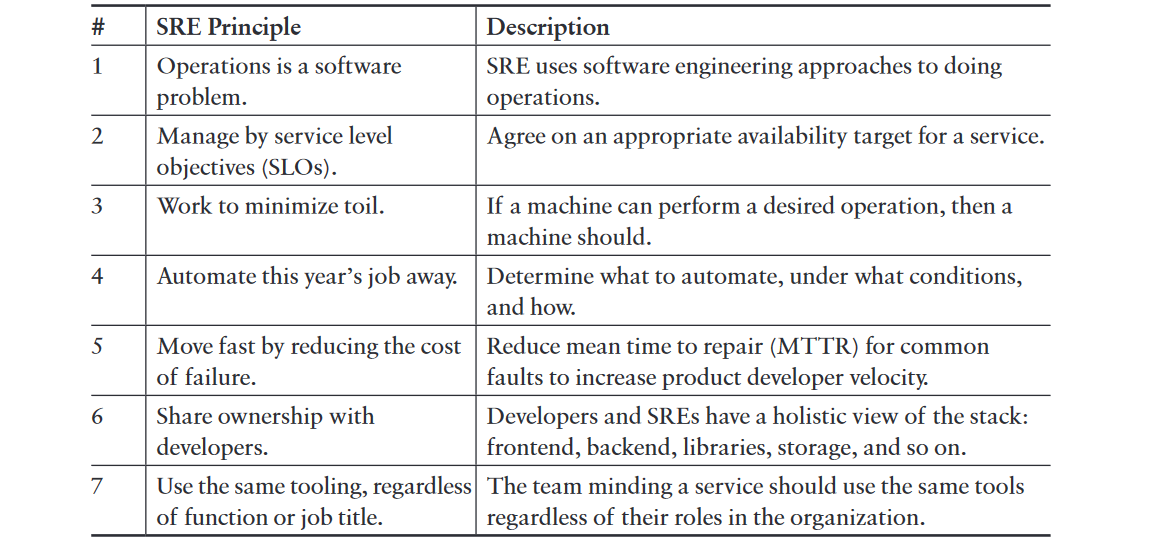
- Hire only coders.
- Have an SLA for your service.
- Measure and report performance against the SLA.
- Use Error Budgets and gate launches on them.
- Have a common staffing pool for SRE and Developers.
- Have excess Ops work overflow to the Dev team.
- Cap SRE operational load at 50 percent.
- Share 5 percent of Ops work with the Dev team.
- Oncall teams should have at least eight people at one location, or six people at each of multiple locations.
- Aim for a maximum of two events per oncall shift.
- Do a postmortem for every event.
- Postmortems are blameless and focus on process and technology, not people.
Terminology

SOW - Scope of Work
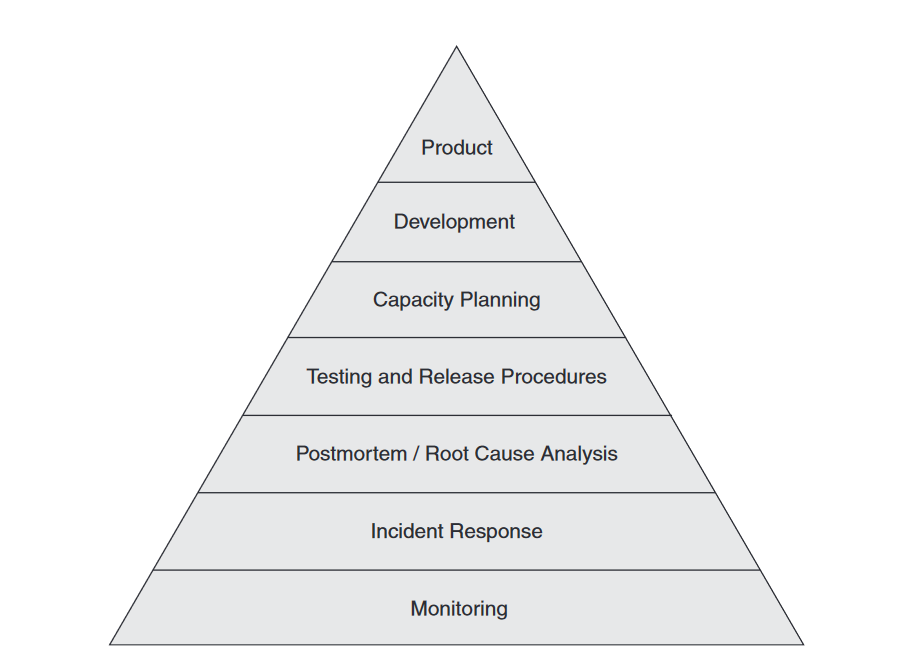
SOW of SRE
- Organizational positioning
- Monitoring construction
- Change management
- Exception response
- Stability governance
- Incident review
- Capacity management
- Cost control
- Activity support
Infrastructure Life Cycle
Lifecycle
- Configuration
- Startup and shutdown
- Queue draining
- Software upgrades
- Backups and restores
- Redundancy
- Replicated databases
- Hot swaps
- Toggles for individual features
- Graceful degradation
- Access controls and rate limits
- Data import controls
- Monitoring
- Auditing
- Debug instrumentation
- Exception collection
SRE Incident Management
Incidents are inevitable in any system. One of the primary roles of an SRE team is to manage these incidents. When such events occur, the SRE team quickly identifies the problem, determines its origin, and implements solutions.
SRE teams utilize various tools and methodologies to handle incidents. Early detection is facilitated through monitoring and alerting systems, allowing for prompt responses. Additionally, post-mortem analyses are conducted to identify the root causes of incidents and to implement measures to prevent their recurrence in the future.
Incident management often involves the following steps:
- Detection: Using monitoring tools to promptly identify incidents.
- Escalation: If the initial team is unable to resolve an issue, it is escalated to a senior member.
- Diagnosis: Determining the root cause of the incident.
- Mitigation: Taking steps to minimize the impact of the incident.
- Resolution: Achieving a final resolution and implementing measures to prevent future recurrences.
Roles in a team

Interview
- Linux Questions
- Python Questions
- Cloud Questions
- System Design Rounds
- Incident management Rounds
- Code review Rounds
- Programming Questions and few programs to practice
- Basic Troubleshooting
- Tools in DevOps
- Tips and Few final words.
Reference
- Establishing SRE Foundations: A Step-by-Step Guide to Introducing Site Reliability Engineering in Software Delivery Organizations (Vladyslav Ukis)
- The Art of Site Reliability Engineering (SRE) with Azure: Building and Deploying Applications That Endure (Unai Huete Beloki)
- Chaos Engineering: Site reliability through controlled disruption (Mikolaj Pawlikowski)
- Hands-on Site Reliability Engineering (Shamayel Mohammed Farooqui; Vishnu Vardhan Chikoti)
https://www.infracloud.io/blogs/sre-best-practices- 《大型网站运维:从系统管理到SRE》
https://github.com/bregman-arie/sre-checklisthttps://sre.google/books/https://www.itprotoday.com/it-operations/how-become-site-reliability-engineer-step-step-guide- SRE in the Real World
https://blog.relyabilit.ie/sre-in-the-real-world/ https://medium.com/automation-avengers/demystifying-sre-devops-and-platform-engineering-understanding-the-differences-5ef37b5d813https://github.com/chowmean/InterviewPreperationForDevOpsAndSREhttps://semaphoreci.com/blog/site-reliability-engineering